Kafka는 MQ(Message Queue)다.
기존 로그 수집 파이프라인은 이렇게 간단했으나, 문제는 서버가 한두대가 아니라는 것이다.
이렇게 간단했으나, 문제는 서버가 한두대가 아니라는 것이다.
모든 로그가 동시 다발적으로 VictoriaLogs에 로그를 Insert하게 되면서 병목현상이 생겨 데이터 처리 지연, 일부 로그 유실이 발생하였다.
그래서 로그 중앙 집중화를 위해 Log Aggregator로 Kafka를 도입하게 되었다.
대용량 로그를 빠르고 안정적으로 처리할 수 있으며, 장애 발생 시에도 로그 유실이 없어 데이터를 안전하게 보존할 수 있다. 그래서
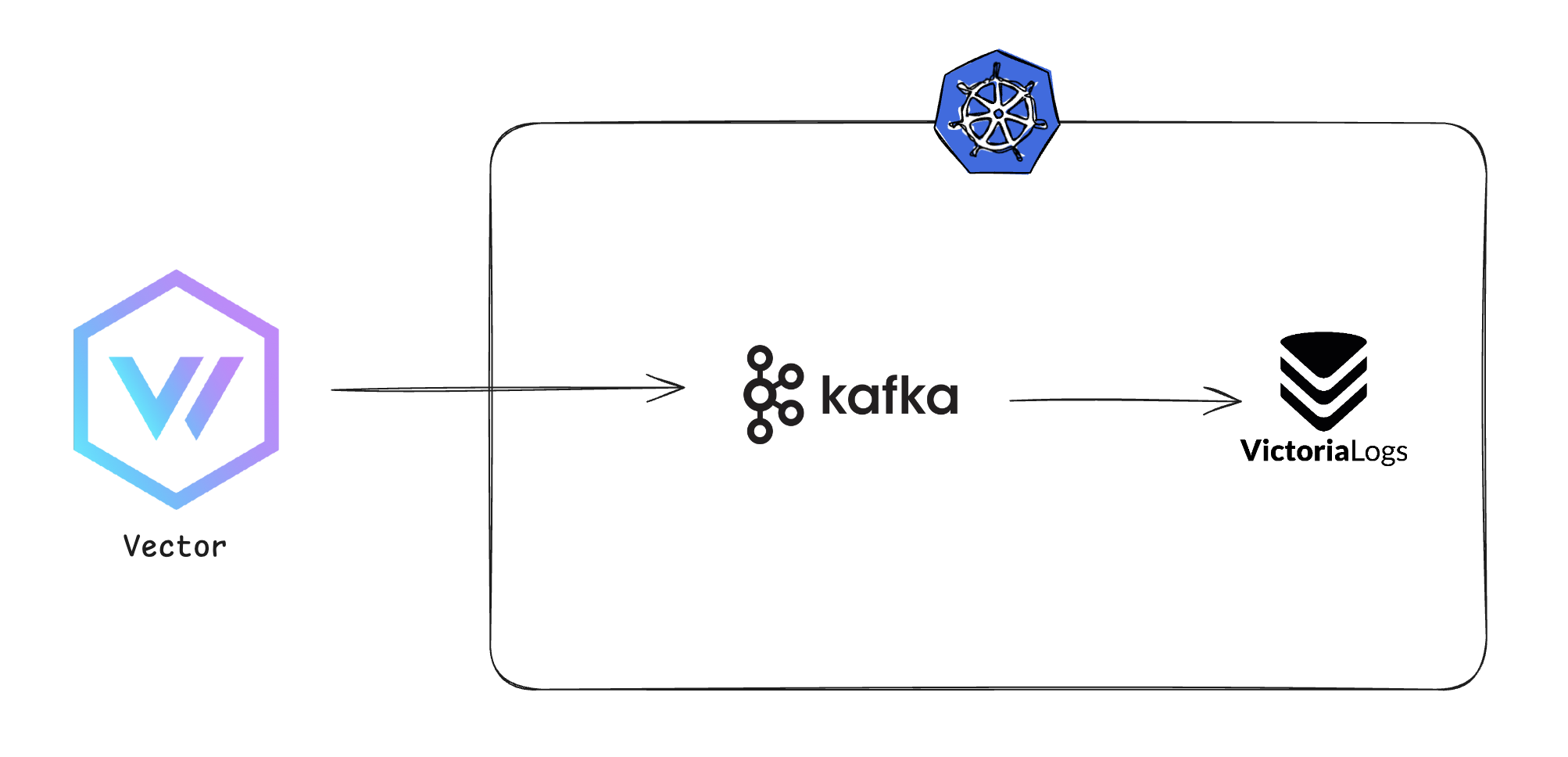 이런 구조를 생각하게 되었으나
이런 구조를 생각하게 되었으나
Kafka는 AMQP와 달리 Consumer가 topic을 구독(sub)하여 소비하는 Pub/Sub모델이며 Consumer가 Pull하는 방식이기 때문에 아래와 같은 구조가 완성되었다.
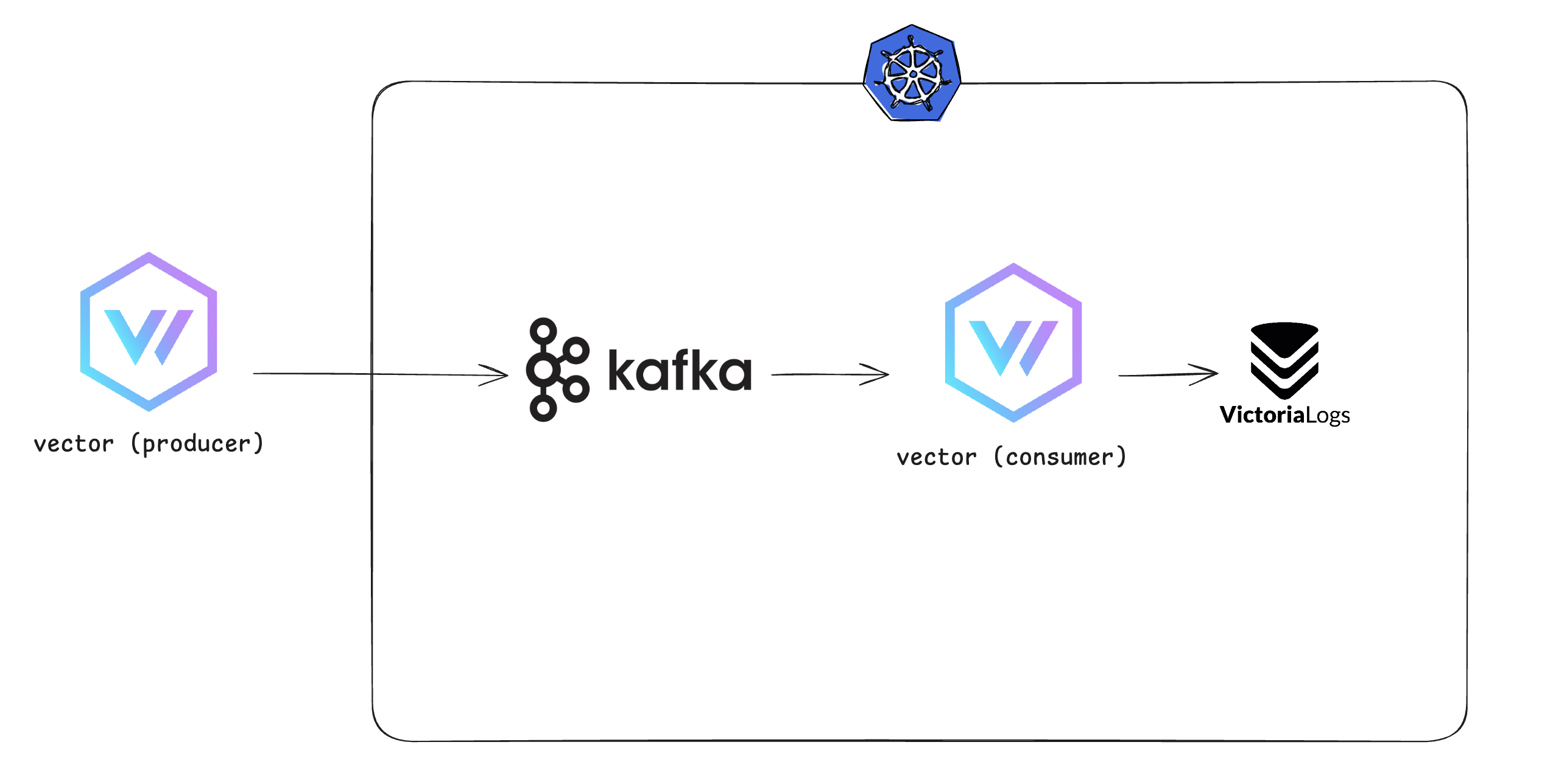
Kafka 배포 - ArgoCD Root Application 배포
우선 Kafka부터 쿠버네티스에 배포하려고 한다.
처음엔 Bitnami Helm chart를 사용했다가 Strimzi Operator를 사용해 배포했다.
나는 ArgoCD의 App of Apps 패턴을 사용중이니 Root Application부터 생성했다.kafka-stack/kafka-cluster.yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: kafka-cluster
namespace: argocd
annotations:
argocd.argoproj.io/sync-wave: "1"
spec:
project: default
destination:
namespace: kafka
server: https://kubernetes.default.svc
source:
path: kafka-stack/kafka/cluster
repoURL: git@github.com:my-repo.git
targetRevision: main
kafka-stack/strimzi-operator.yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: strimzi-operator
namespace: argocd
annotations:
argocd.argoproj.io/sync-wave: "0"
spec:
project: default
destination:
namespace: kafka
server: https://kubernetes.default.svc
source:
chart: strimzi-kafka-operator
repoURL: https://strimzi.io/charts
targetRevision: 0.45.0
helm:
values: |
watchNamespaces:
- kafka
 이렇게 생성이 된다.
이렇게 생성이 된다.
이제 kafka-cluster를 만들어준다.
Kafka 배포 - Operator Resources
kafka/kafka/cluster
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: controller
labels:
strimzi.io/cluster: log-aggregator-kafka
spec:
replicas: 3
roles:
- controller
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
kraftMetadata: shared
deleteClaim: false
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: broker
labels:
strimzi.io/cluster: log-aggregator-kafka
spec:
replicas: 3
roles:
- broker
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
kraftMetadata: shared
deleteClaim: false
---
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: log-aggregator-kafka
annotations:
strimzi.io/node-pools: enabled
strimzi.io/kraft: enabled
spec:
kafka:
version: 3.9.0
metadataVersion: 3.9-IV0
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
- name: external
port: 9094
type: ingress
tls: true
configuration:
bootstrap:
host: kafka.my-kafka.com
brokers:
- broker: 0
host: broker-0.my-kafka.com
- broker: 1
host: broker-1.my-kafka.com
- broker: 2
host: broker-2.my-kafka.com
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
default.replication.factor: 3
min.insync.replicas: 2
entityOperator:
topicOperator: {}
userOperator: {}
Strimzi-operator의 CRD를 사용해 Kafka를 배포한다.
클러스터 외부의 접근이 필요하기 때문에 nodePort, ingress, LoadBalancer 등등 알아보다가 결국 ingress방식으로 했다.Cert-manager로 발급받는 자동갱신 SSL 인증서가 있기 때문에 주기적으로 관리할 필요도없고,
NodePort는 Pod가 재생성 될때 다른 노드에 스케줄되면 Vector로 로그를 수집하고있는 모든 서버의 설정을 바꿔야 하기 때문에 Ingress를 사용하기로 했다.
 당연하게도! 잘 배포가 되었다.
당연하게도! 잘 배포가 되었다.
Vector Sink 수정
Vector는 굉장히 많은 Sink를 지원한다. Loki, VictoriaLogs, ElasticSearch, Datadog, Kafka 등등등.. 웬만한 솔루션을 지원한다.
기존설정
data_dir: "/etc/vector"
sources:
logs:
type: file
include:
- /path/to/logs/*.log
transforms:
transformed_logs:
type: remap
inputs:
- logs
source: |
if .message == "" {
abort
}
._msg = .message
.component = my-component
.host_ip = 192.168.1.25
sinks:
vlogs:
inputs:
- transformed_logs
type: elasticsearch
endpoints:
- https://my-vlog.com/insert/elasticsearch/
api_version: v8
compression: gzip
healthcheck:
enabled: false
query:
_msg_field: message
_time_field: timestamp
_stream_fields: host,container_name
debug:
inputs:
- transformed_logs
type: console
encoding:
codec: json
기존의 설정은 VictoriaLogs로 바로 Sink했다.
이제 VictoriaLogs가 아닌 Kafka로 보낼 것이니 Sink부분만 수정했다.
그 전에 아래의 명령어로 Kafka Cluster의 인증서파일을 가져온다.kubectl get secret log-aggregator-kafka-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crt
이 ca파일을 로그수집할 서버에 옮겨주고 아래와 같이 Sink를 수정한다.
sinks:
vlogs:
inputs:
- transformed_logs
type: kafka
bootstrap_servers: "kafka.my-kafka.com:443"
topic: "standard-logs"
tls:
enabled: true
ca_file: /etc/vector/ca.crt
encoding:
codec: json
compression: gzip
healthcheck:
enabled: false
debug:
inputs:
- transformed_logs
type: console
encoding:
codec: json
이 서버의 Vector는 로그를 수집하고 Kafka로 보내는데 standard-logs라는 topic 으로 보낸다.
위에서 언급했듯 Kafka는 Consumer가 topic을 구독(Sub)하는 구조이기 때문에 Consumer가 이 topic을 구독함으로써 메세지를 소비할 수 있게 된다.
만약 정상적으로 메세지를 Kafka에 보내는지 확인하고 싶다면 아래의 명령어를 실행한다.
kubectl exec -it log-aggregator-kafka-broker-0 -c kafka -- \
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
메세지가 보내진다면 내가 Vector에서 지정한 topic이 생긴다.

Consumer 배포
메세지가 정상적으로 Kafka에 보내지는것을 확인했으니, 이제 이 메세지를 Consume해서 VictoriaLogs에 보낼 Consumer가 필요하다.
직접 만들어도 되고, 여러 솔루션이 많겠지만 나는 Vector를 사용했다.
VRL(Vector Remap Language)를 통해 수집된 로그들에게 공통 라벨을 붙인다던지, 커스텀이 쉽기 때문에 선택했다.
Vector역시 Helm chart를 이용해 같은 네임스페이스 안에 배포했다.
role: "Stateless-Aggregator"
logLevel: "debug"
customConfig:
data_dir: /vector-data-dir
api:
enabled: true
address: 127.0.0.1:8686
sources:
kafka_logs:
type: kafka
bootstrap_servers: log-aggregator-kafka-kafka-bootstrap.kafka.svc.cluster.local:9092
topics:
- standard-logs
group_id: vector-consumer
auto_offset_reset: earliest
transforms:
kafka_parser:
type: remap
inputs: [kafka_logs]
source: |
. = parse_json!(.message)
.component = .component
.host_ip = .host_ip
sinks:
victoria_logs:
type: elasticsearch
inputs: [kafka_parser]
endpoints:
- http://victoria-logs-victoria-logs-single-server.victoria.svc.cluster.local:9428/insert/elasticsearch/
compression: gzip
api_version: v8
healthcheck:
enabled: false
query:
_msg_field: message
_time_field: timestamp
_stream_fields: [host, kubernetes.pod_name]
- customConfig.sources:
kafka로 부터 consume한다. 위에서 Vector -> Kafka로 Publish 할 때 정한 topic을 그대로 구독하고, vector-consumer라는consumer group id를 줬다. - customConfig.transforms:
위에서 말한VRL부분이다. 서버에서component,host_ip와 같은 라벨을 붙여서 Kafka에 보내는데, 위처럼 매핑해주지 않으면 Kafka -> VictoriaLogs로 보낼때(소비할 때)는 나타나지 않는다.
이제 아래의 명령어로 확인을 해본다

LAG는 CURRENT-OFFSET과 LOG-END-OFFSET의 차이이다.
즉 큐에 쌓였는데 아직 소비하지 않고 남은 메세지 이다.
이제 VictoriLogs에 확인해보면
 당연하게도 잘 나온다.
당연하게도 잘 나온다.
마무리
사실 이 구조를 완성하는데 3~4일 정도 걸렸다. 난 RabbitMQ만 다뤄봐서 Kafka도 비슷하겠거니 했는데 아무래도 쓰이는 용어가 다르다 보니 좀 헷갈렸다.
또 배포하고 Vector랑 연결할때도 애를 먹었는데 막상 글로 쓰려니까 어떻게 써야할지 모르겠어서 그냥 안썼다.
이제 해결해야할 문제는 일부 오래된서버의 OS가 CentOS 6이기 때문에 Vector를 지원하지않는다 (GLIBC 버전 문제)
그렇기 때문에 Promtail을 쓰고 있었는데 Promtail은 Loki 클라이언트라서 Kafka로 보내는기능이 없다(게다가 Promtail은 이제 Deprecated다)
이 문제만 해결하면 로깅파이프라인은 한동안 안정적일 것 같다.